
今回はディープラーニング用ライブラリのPyTorchを利用し、ニューラルネットワークのモデルを構築してクラス分類を行う方法について書きます。
本記事における用語の説明

まずはいくつか用語の説明をします。
既に知っているという方は読み飛ばして下さい。
クラス分類とは
対象となるデータがいくつかのグループの内どれに属するのかを予測することです。
例としては、スパムメールの分類(受信メールがスパムか否かを予測)などが挙げられます。
ニューラルネットワークとは
AI関連技術である機械学習の代表的な手法の一つです。
基本単位のニューロンがいくつも連結することでネットワークを構築し、これを利用して様々な予測を行います。
ニューラルネットワークの内部は、一番最初にデータが入力される入力層、計算結果を出力する出力層、入力層と出力層の間の隠れ層のどれかに分類されます。
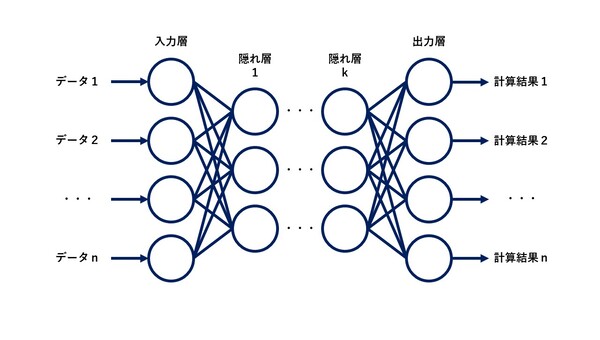
各層では入力された値を基に計算を行い、その計算結果を次の層のニューロンへ入力するという流れを入力層から出力層まで繰り返します。
各ニューロンにはどの入力を重要視するかを決定する重みがそれぞれ設定されており、重みの値を調整することで望ましい出力を得ることが可能です。
なお、ニューラルネットワークのメリット、デメリットはそれぞれ以下のようになります。
- メリット:
層やニューロンの数を増やすことで容易にモデルを拡張できる(層やニューロンの数が多いほど、高い性能が得られやすい) - デメリット:
構造が複雑でブラックボックス化しやすく、何故その結果が得られるのかがわかりにくい
実際にプログラムを作成してみる

それでは実際にニューラルネットワークのモデルを構築してクラス分類を行うプログラムを作成してみます。
プログラム作成の手順
ここでは、以下の手順で処理を実装します。
- 実験用のデータセットを用意する
- データセットの一部を利用して学習(モデルの構築)を行う
- 構築したモデルを用いて残りのデータセットに対する予測を行う
今回に限らず機械学習のモデルを構築する際には上記のような手順で実行することが多いです。
使用する実験用データセット
機械学習モデルの実験を行うには、当然、モデルに入力するデータが必要です。
今回は簡単なデータセットを自作して利用します。
作成するのは、以下のような2クラスのデータ(2次元ベクトル)です。
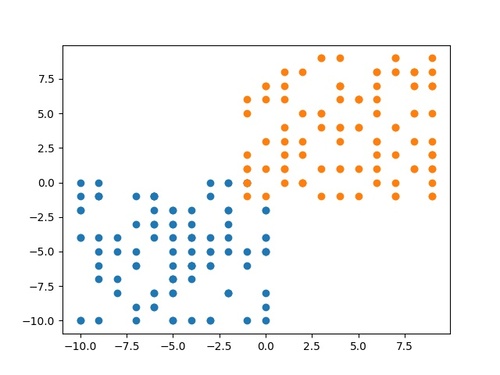
具体的なデータの作り方については、後ほど紹介するサンプルプログラムを参照して下さい。
モデルのハイパーパラメータ設定
今回はニューラルネットワークの分類モデルを以下の条件で構築します。
- 隠れ層の数:2
↳ ニューロンの数:(5, 5, ) - 活性化関数:
↳ 出力層以外:ReLU関数
↳ 出力層 :Softmax関数 - 最適化アルゴリズム:SGD
- 損失関数:クロスエントロピー関数
具体的な実装方法については、後ほど紹介するサンプルプログラムを参照して下さい。
実装例
上記の手順に従ってプログラムを作成します。使用する言語はPythonです。
import torch
# ニューラルネットワークの分類モデルのクラス
class NNClassifier(torch.nn.Module):
# コンストラクタ
def __init__(self, input_size, output_size):
super(NNClassifier, self).__init__()
self.fc1 = torch.nn.Linear(input_size, 5)
self.fc2 = torch.nn.Linear(5, 5)
self.fc3 = torch.nn.Linear(5, output_size)
# 順伝播の計算を行うメソッド
def forward(self, x):
y = torch.nn.functional.relu(self.fc1(x))
y = torch.nn.functional.relu(self.fc2(y))
y = torch.nn.functional.softmax(self.fc3(y))
return y
if __name__ == '__main__':
train_size = 100
test_size = 100
data_size = train_size + test_size
class_num = 2
class_size = int(data_size / class_num)
# 実験用データセットの説明変数を作成
x_class1 = torch.randint(-10, 1, (class_size, 2))
x_class2 = torch.randint(-1, 10, (class_size, 2))
x = torch.cat((x_class1, x_class2), 0)
# 実験用データセットの目的変数を作成
t_class1 = torch.Tensor([[0, 1]] * class_size)
t_class2 = torch.Tensor([[1, 0]] * class_size)
t = torch.cat((t_class1, t_class2), 0)
perm = torch.randperm(data_size)
# データセットを学習用とテスト用に分割
i_train, i_test = perm[:train_size], perm[train_size:]
x_train, x_test = x[i_train].float(), x[i_test].float()
t_train, t_test = t[i_train].float(), t[i_test].float()
input_size = x.size()[1]
output_size = t.size()[1]
nnc = NNClassifier(input_size, output_size)
nnc.train()
lr = 0.01
n_epochs = 20
# 最適化アルゴリズムと損失関数を定義
optimizer = torch.optim.SGD(nnc.parameters(), lr=lr)
criterion = torch.nn.CrossEntropyLoss()
# モデルの学習を実施
for epoch in range(n_epochs):
for x, t in zip(x_train, t_train):
nnc.zero_grad()
y = nnc(x)
loss = criterion(t.view(1, -1), y.view(1, -1))
loss.backward()
optimizer.step()
print('( Train ) Epoch : %.2d, Loss : %f' % (epoch + 1, loss))
# モデルのテストを実施
print('-------------------------------------')
y_test = nnc(x_test)
score = torch.sum(torch.argmax(y_test, axis=1) == torch.argmax(y_test, axis=1)) / test_size
print('( Test ) Accuracy Score : %f' % score)このプログラムを実行すると以下の出力結果が得られます。
( Train ) Epoch : 01, Loss : 0.555741 ( Train ) Epoch : 02, Loss : 0.531510 ( Train ) Epoch : 03, Loss : 0.502515 ( Train ) Epoch : 04, Loss : 0.469323 ( Train ) Epoch : 05, Loss : 0.445897 ( Train ) Epoch : 06, Loss : 0.428990 ( Train ) Epoch : 07, Loss : 0.416270 ( Train ) Epoch : 08, Loss : 0.406224 ( Train ) Epoch : 09, Loss : 0.398009 ( Train ) Epoch : 10, Loss : 0.391198 ( Train ) Epoch : 11, Loss : 0.385432 ( Train ) Epoch : 12, Loss : 0.380474 ( Train ) Epoch : 13, Loss : 0.376151 ( Train ) Epoch : 14, Loss : 0.372347 ( Train ) Epoch : 15, Loss : 0.368967 ( Train ) Epoch : 16, Loss : 0.365936 ( Train ) Epoch : 17, Loss : 0.363149 ( Train ) Epoch : 18, Loss : 0.360515 ( Train ) Epoch : 19, Loss : 0.358131 ( Train ) Epoch : 20, Loss : 0.355962 ------------------------------------- ( Test ) Accuracy Score : 1.000000
学習を通して損失関数の値が減少し、テストでも正答率100%という高い値が得られています。
このことから十分な性能のニューラルネットワークの分類モデルを構築できたと考えられます。


