
本記事では、機械学習ライブラリのscikit-learnを利用して、決定木のアルゴリズムに基づいて回帰分析を行う方法について書きます。
本記事における用語の説明

まずはいくつか用語の説明をします。
既に知っているという方は読み飛ばして下さい。
回帰分析とは
対象のデータから特定の数値を予測するための統計的手法のことです。
例としては、株価の予測(金利や為替などの情報から株価を予測)などが挙げられます。
決定木とは
AI関連技術である機械学習の代表的な手法の一つです。基本単位のノードがいくつも繋がった有向グラフのような構造をしています。
各ノードはそれぞれの位置、役割から以下のような分類となります。
- 最上位のノード(根ノード):
予測対象となるデータは最初にこのノードへ入力される - 最下位のノード(葉ノード):
入力されたデータは最後にこのノードへ到達する - それ以外のノード:
設定された条件式に従ってデータを次のノードへ遷移させる
決定木では、入力されたデータの値に基づいて根ノードから次々とノードを遷移していき、最終的にどの葉ノードに到達するかで出力の値を決定します。
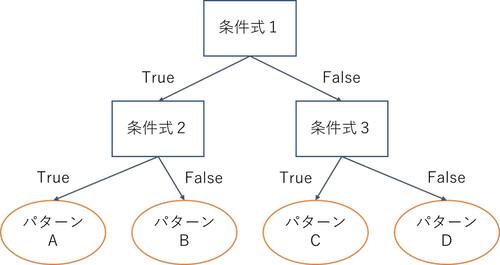
ノードの数や条件式は、学習データに対する予測を行う上で最適なものが設定されるようになっています。
なお、決定木のメリット、デメリットはそれぞれ以下の通りです。
- メリット:
数値データ、カテゴリデータなど、複数種のデータが混在したデータセットも扱うことが可能 - デメリット:
性能が学習データにかなり依存するため頑健なモデルを構築しずらい
実際にプログラムを作成してみる

それでは、決定木のアルゴリズムに基づいて回帰分析を行うプログラムを作成してみます。
プログラム作成の手順
ここでは、以下の手順で処理を実装します。
- 実験用のデータセットを用意する
- データセットの一部を利用して学習(モデルの構築)を行う
- 構築したモデルを用いて残りのデータセットに対する予測を行う
今回に限らず、機械学習のモデルを構築する際には上記手順で実行することが多いです。
使用する実験用データセット
scikit-learnには、学習やテストで使用する実験用のデータセットが用意されているため、今回はその中の一つのボストンの住宅価格データ(load_boston)を使用します。
使用するデータセットの概要は以下の通りです。
- 用途:回帰
- データ件数:506
- データ次元数:13
- ドキュメント:sklearn.datasets.load_boston
ボストン市内の地域ごとの犯罪率や税率などの情報(13項目)を入力データとしてその地域の住宅価格を予測します。
モデル構築に使用するクラス
scikit-learnには、決定木のアルゴリズムに基づいて回帰分析の処理を行うDecisionTreeRegressorクラスが存在するため、今回はこれを利用します。
DecisionTreeRegressorの主なパラメータは以下の通りです。(一部省略)
- criterion:{‘mse’, ‘friedman_mse’, ‘mae’, ‘poisson’}
学習時、モデルの評価に使用する指標 - splitter:{‘best’, ‘random’}
各ノードの条件式の設定方法 - max_depth:int型 or None
決定木の深さの最大値(Noneの場合は、深さの制限無し) - random_state:int型
乱数のシードを指定する
DecisionTreeRegressorはsklearn.treeパッケージからインポートします。
実装例
上記の手順に従ってプログラムを作成します。使用する言語はPythonです。
from sklearn.datasets import load_boston
from sklearn.tree import DecisionTreeRegressor
import random
if __name__ == '__main__':
# データセットを読み込む
boston = load_boston()
x = boston.data
y = boston.target
# 読み込んだデータセットをシャッフルする
p = list(zip(x, y))
random.shuffle(p)
x, y = zip(*p)
# 学習データの件数を指定する
train_size = 300
test_size = len(x) - train_size
# データセットを学習データとテストデータに分割する
train_x = x[:train_size]
train_y = y[:train_size]
test_x = x[train_size:]
test_y = y[train_size:]
# 決定木の学習を行う
tree = DecisionTreeRegressor(criterion='mse', max_depth=None)
tree.fit(train_x, train_y)
# 学習させたモデルを使ってテストデータに対する予測を出力する
pred = tree.predict(test_x)
for i in range(test_size):
c = test_y[i]
p = pred[i]
print('[{0}] correct:{1:.3f}, predict:{2:.3f} ({3:.3f})'.format(i, c, p, c-p))
# 予測結果から決定係数を算出する
print('R^2 = {0}'.format(tree.score(test_x, test_y)))このプログラムを実行すると以下の出力結果が得られます。
[0] correct:13.400, predict:11.800 (1.600) [1] correct:20.200, predict:23.200 (-3.000) [2] correct:15.600, predict:15.200 (0.400) ...省略... [203] correct:23.800, predict:20.300 (3.500) [204] correct:20.600, predict:22.900 (-2.300) [205] correct:24.100, predict:23.300 (0.800) R^2 = 0.837366639258301
出力結果の最後の行は「決定係数」の値です。
決定係数とは、回帰分析において正解の値と予測値の誤差を算出した指標であり、その値が1.0に近いほど良い予測性能であると評価されます。
一般的に決定係数が0.6以上あれば予測モデルとして一定の性能を持つとされているため、上記のプログラムで構築したモデルは十分な予測性能であると判断できます。


