
構築した機械学習モデルのテストを行う際に、分類予測の結果を混同行列として出力することがしばしばあります。
本記事では、scikit-learnのconfusion_matrixメソッドを用いて混同行列を出力する方法、及び出力した混同行列をヒートマップにプロットする方法について書きます。
そもそも「混同行列」とは?

まずは混同行列とは何かについて簡単に説明します。
分類予測の内訳を表す行列
混同行列とは、それぞれの入力データが分類モデルの予測において、どのクラスに分類されたのかを表す行列のことです。
以下に混同行列の例を一つ示します。
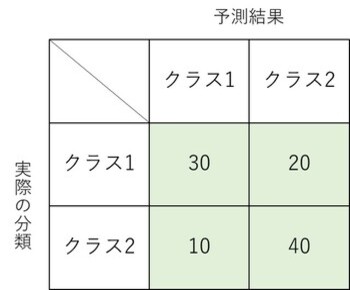
この例からは以下の事実が読み取れます。
- クラス1であると予測され、実際の分類もクラス1のデータが30件
- クラス2であると予測され、実際の分類もクラス2のデータが40件
- クラス1であると予測されたが、実際の分類はクラス2のデータが10件
- クラス2であると予測されたが、実際の分類はクラス1のデータが20件
このように分類予測の結果を混同行列として表すことでその内訳を一目で把握できるようになります。
実際にプログラムを作成してみる

それでは、実際に分類予測の結果から混同行列を生成するプログラムを作成してみます。
プログラム作成の手順
ここでは、以下の手順で処理を実装します。
- 実験用データセットを用意する(学習用とテスト用に分割)
- データセットを用いて分類モデルを構築する
- 構築した分類モデルのテストを行う
- テストデータに対する予測結果から混同行列を生成する
混同行列の生成に利用するメソッド
scikit-learnには、分類予測の結果から混同行列を生成するconfusion_matrixメソッドが存在するため、今回はこれを利用します。
confusion_matrixメソッドの引数、及び戻り値はそれぞれ以下の通りです。
- 引数:正解ラベル(1次元配列)、予測結果(1次元配列)
- 戻り値:混同行列(2次元配列)
なお、confusion_matrixメソッドはsklearn.metricsからインポートします。
実装例
上記の手順に従ってプログラムを作成します。使用する言語はPythonです。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neural_network import MLPClassifier
from sklearn.metrics import confusion_matrix
if __name__ == "__main__":
#データセットの読み込み
iris = load_iris()
x = iris.data
y = iris.target
#データセットの分割
train_x, test_x, train_y, test_y = train_test_split(x,y)
#モデルの学習&予測
mlp = MLPClassifier()
pred_y = mlp.fit(train_x, train_y).predict(test_x)
#混同行列の生成
cm = confusion_matrix(test_y, pred_y)
print(cm)このプログラムを実行すると以下の出力結果が得られます。
[[15 0 0] [ 0 11 2] [ 0 0 10]]
無事に混同行列を生成することができました。
ただ、これだけでは数値の羅列にしか見えず、内容がわかりにくいかもしれません。
もっと見やすい表にするためには、各行に対応するラベルの情報を自分で追加するなどの工夫が必要です。
応用編:混同行列をヒートマップへ

confusion_matrixメソッドの戻り値である混同行列(2次元配列)をそのまま表示するだけでは、かなり中身が見づらいです。
このような事態を解決する方法としては、得られた混同行列をヒートマップとしてプロットすることが挙げられます。
ここでは、混同行列をヒートマップとしてプロットするプログラムの作成方法を紹介します。
プログラム作成の手順
ここでは、以下の手順で処理を実装します。
- 実験用データセットを用意する(学習用とテスト用に分割)
- データセットを用いて分類モデルを構築する
- 構築した分類モデルのテストを行う
- テストデータに対する予測結果から混同行列を生成する
- 混同行列をヒートマップとしてプロットする
実装例
上記の手順に従ってプログラムを作成します。使用する言語はPythonです。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neural_network import MLPClassifier
from sklearn.metrics import confusion_matrix
from sklearn.utils.multiclass import unique_labels
import matplotlib.pyplot as plt
import numpy as np
def plot_confusion_matrix(test_y, pred_y, class_names, normalize=False):
cm = confusion_matrix(test_y, pred_y)
classes = class_names[unique_labels(test_y,pred_y)]
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
fig, ax = plt.subplots()
im = ax.imshow(cm, interpolation='nearest', cmap=plt.cm.Blues)
ax.figure.colorbar(im, ax=ax)
ax.set(xticks=np.arange(cm.shape[1]),
yticks=np.arange(cm.shape[0]),
xticklabels=classes,
yticklabels=classes,
ylabel='True label\n',
xlabel='\nPredicted label')
fmt = '.2f' if normalize else 'd'
for i in range(cm.shape[0]):
for j in range(cm.shape[1]):
ax.text(j, i, format(cm[i, j], fmt), ha="center", va="center")
fig.tight_layout()
return ax
if __name__ == "__main__":
#データセットの読み込み
iris = load_iris()
x = iris.data
y = iris.target
class_names = iris.target_names
#データセットの分割
train_x, test_x, train_y, test_y = train_test_split(x, y, test_size=100)
#モデルの学習&予測
mlp = MLPClassifier()
pred_y = mlp.fit(train_x, train_y).predict(test_x)
#混同行列をヒートマップにプロット
plot_confusion_matrix(test_y, pred_y, class_names)
plt.show()このプログラムを実行すると以下の出力結果が得られます。
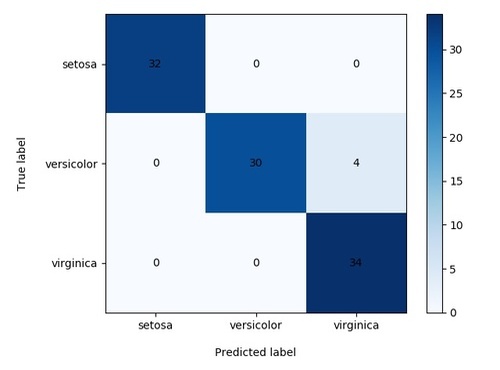
これでかなり見やすくなりました。


